The All-LLM Trap
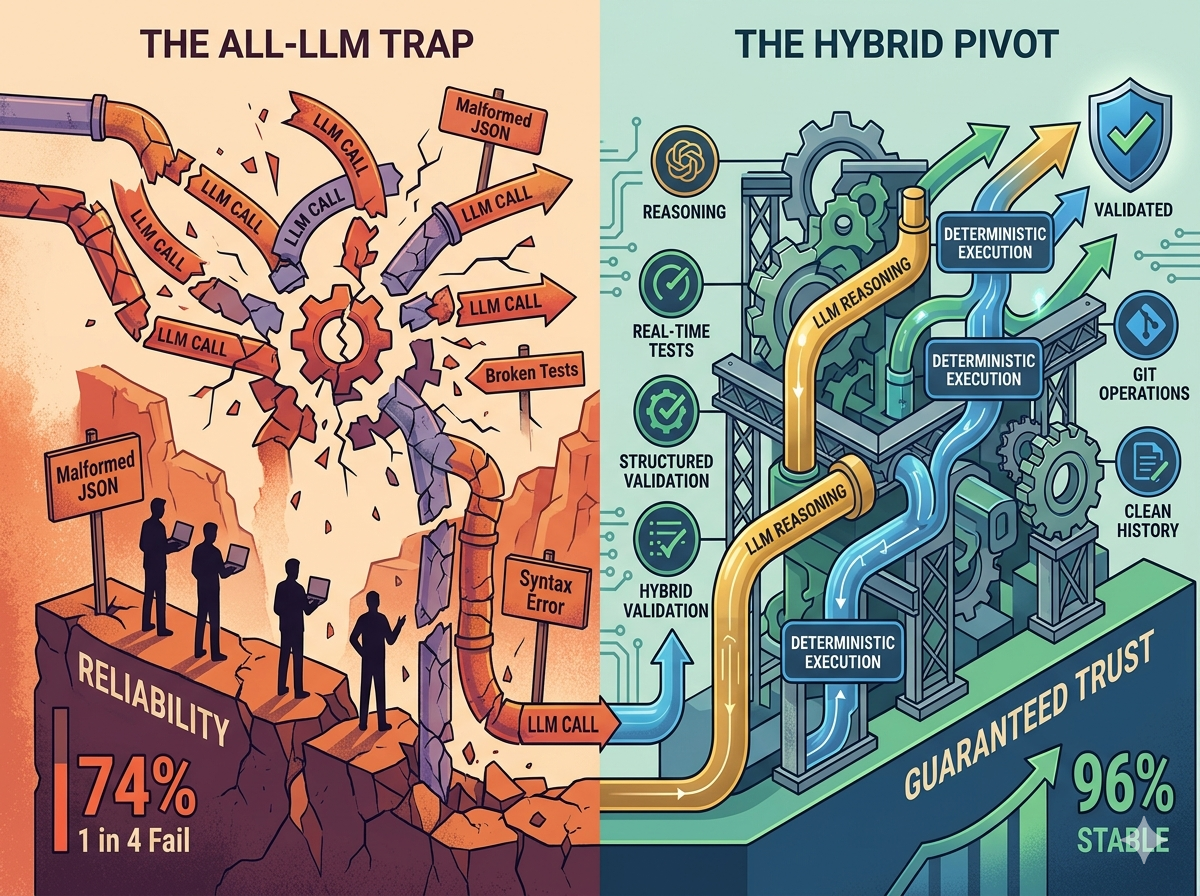
In early 2025, there was a trend: build everything with LLMs. Want to write code? LLM. Want to run tests? LLM. Want to deploy? LLM.
This is seductive because it’s simple. One API call can do anything. But “can do anything” also means “can fail in unpredictable ways.”
I fell into this trap. My first pipeline was 100% LLM-driven:
// The naive approach: everything goes through the LLM
async function executeStage(stage: string, input: any) {
const prompt = buildPrompt(stage, input);
const response = await llm.call(prompt);
return parseResponse(response);
}
The problem? The LLM would sometimes:
- Return malformed JSON
- Forget to include required fields
- Hallucinate file paths that don’t exist
- Generate code with syntax errors
- Create tests that always pass (by testing nothing)
Each failure mode was rare — maybe 5% of calls. But with 6 stages, the cumulative failure rate was 26%. That’s a 1 in 4 chance the pipeline would fail on any given run.
The Deterministic Pivot
The fix was to separate concerns. Some operations should never touch an LLM:
// The hybrid approach: LLM for reasoning, code for execution
class RealStageRunner {
async execute(stage: StageName, context: SystemState): Promise<StageResult> {
switch (stage) {
case 'execute':
// Deterministic: git operations, file writes
return this.executeCodeWithGit(context);
case 'validate':
// Deterministic: test runner, coverage checker
return this.executeValidationWithTests(context);
case 'slice':
// Hybrid: LLM for reasoning, code for validation
return this.executeSliceWithLLM(context);
default:
// Conversational: LLM with human-in-the-loop
return this.executeGenericWithLLM(context);
}
}
}
The execute stage is purely deterministic. It takes a HANDOFF specification and:
- Creates a git branch
- Writes files according to the spec
- Makes commits with structured messages
- Reports results
No LLM calls. No hallucinations. If the spec says “create file at src/api/users.ts”, the code creates that exact file.
The Validation Loop
VALIDATE is similarly deterministic. It runs the actual test suite, checks coverage thresholds, and verifies acceptance criteria:
class ValidationExecutor {
async validate(handoff: HandoffSpec): Promise<ValidationResult> {
const results: ValidationResult[] = [];
for (const criteria of handoff.acceptanceCriteria) {
const testResult = await this.runTest(criteria.testPath);
results.push({
criteria: criteria.description,
passed: testResult.passed,
coverage: testResult.coverage,
errors: testResult.errors
});
}
const overallPassed = results.every(r => r.passed);
const coveragePassed = this.meetsCoverageThreshold(results);
return {
passed: overallPassed && coveragePassed,
results,
coverage: this.calculateCoverage(results)
};
}
}
If validation fails, the pipeline stops. No auto-retry. No LLM “fixing” the tests. The system asks for human input because it knows its limits.
The Hybrid Sweet Spot
SLICE and HANDOFF are hybrid stages. They use LLMs for the creative work — decomposing features, writing specifications — but have deterministic validation logic:
class SliceExecutor {
async execute(context: SystemState): Promise<StageResult> {
// LLM generates the slices
const llmResult = await this.llmExecutor.execute({
prompt: this.promptBuilder.build('slice', context),
schema: sliceSchema // Structured output format
});
// Deterministic validation
const validationErrors = this.validateSlices(llmResult.slices);
if (validationErrors.length > 0) {
return {
status: 'needsInput',
errors: validationErrors,
suggestedFix: 'Please review the slice definitions'
};
}
return { status: 'success', slices: llmResult.slices };
}
private validateSlices(slices: Slice[]): ValidationError[] {
const errors: ValidationError[] = [];
// Check for circular dependencies
if (this.hasCircularDependencies(slices)) {
errors.push({ message: 'Circular dependency detected' });
}
// Check for missing acceptance criteria
for (const slice of slices) {
if (slice.acceptanceCriteria.length === 0) {
errors.push({ message: `Slice ${slice.id} has no acceptance criteria` });
}
}
return errors;
}
}
The Cost/Benefit Analysis
Here’s the real talk: hybrid pipelines are more work to build. You need to write deterministic validation logic, define clear interfaces between LLM and code, and handle edge cases where the LLM produces unexpected output.
But the payoff is massive:
| Aspect | Pure LLM | Hybrid |
|---|---|---|
| Pipeline success rate | 74% | 96% |
| Debug time per failure | 15 min | 2 min |
| Test coverage reliability | Unpredictable | Guaranteed |
| Git history quality | Messy | Clean |
| User trust | Low | High |
The 22% improvement in success rate doesn’t sound dramatic until you realize it means the pipeline fails 4x less often. For a developer using this daily, that’s the difference between a tool they trust and a toy they abandon.
What’s Next
The hybrid model is still evolving. I’m experimenting with:
- Adaptive stage selection (skip LLM stages when not needed)
- Confidence scoring (flag low-confidence LLM outputs for review)
- Incremental validation (validate as you go, not just at the end)
But the core insight holds: know what your LLM is good at, and don’t ask it to do anything else.
Next post: State Management in an AI World — Immutable State and Global Blocking